Basic Filters and commands in unix systems
This UNIX command utility scans a file by lines and also split the each line into columns based on default delimiter. Then match input fields/pattern to lines and also performs the specified actions on the matching line.
basic Builtin-variables:
NR : current record number in the total input stream.
NF : number of fields in the current record.
example:
~$ ls -l //list current directory files and folders
~$ ls -l > testfile5 //save the list current directory files and folders to the testfile5
~$ awk '{print $1,$6}' testfile5 //select the column 1 and 6 from the testfile5 and display

2. cat command:
The cat ("concatenate" ) is filter command of operating systems like Linux/Unix. cat utility command used to create one or more files, view content of file, concatenate different files and can redirect the output to files or terminal.
example:
~$ cat > testfile1 // to create file, exit terminal and save the file content after pressing CTRL+D.
~$ cat testfile //command to display the content of the file to terminal
~$ cat testfile3 >> testfile // Append the content of testfile3 to the end of testfile2.
 3. comm command:
3. comm command:
~$ cat testfile6 //displays the content of testfile6
~$ cat testfile7 //displays the content of testfile7
~$ comm testfile6 testfile7
In output of the above command,
First column shows distinct lines in testfile6
Second column shows distinct lines in testfile7
Third column shows lines common in both files

4. head command:

9 . tr command:
~$cat testfile3 | tr “[a-z]” “[A-Z]”

10 . uniq command:

- Commands in unix OS are case-sensitive i.e 'CLEAR' is different from 'clear' command. (if you try to run the CLEAR in terminal (it shows "command not found" message), 'clear' command will clear the terminal space)
This UNIX command utility scans a file by lines and also split the each line into columns based on default delimiter. Then match input fields/pattern to lines and also performs the specified actions on the matching line.
basic Builtin-variables:
NR : current record number in the total input stream.
NF : number of fields in the current record.
example:
~$ ls -l //list current directory files and folders
~$ ls -l > testfile5 //save the list current directory files and folders to the testfile5
~$ awk '{print $1,$6}' testfile5 //select the column 1 and 6 from the testfile5 and display

The cat ("concatenate" ) is filter command of operating systems like Linux/Unix. cat utility command used to create one or more files, view content of file, concatenate different files and can redirect the output to files or terminal.
example:
~$ cat > testfile1 // to create file, exit terminal and save the file content after pressing CTRL+D.
~$ cat testfile //command to display the content of the file to terminal
~$ cat testfile3 >> testfile // Append the content of testfile3 to the end of testfile2.

- comm UNIX command compare two sorted files line by line and display in (terminal) standard output.
- Suppose there are two file, file1 contains the list of the student names opted for subject DBMS and file2 contains the list of the student names opted for subject OS. To find the student names who are common in both files then, comm command will help you to achieve result for above query.
- To run this comm command content of the files to compare should be sorted.
~$ cat testfile6 //displays the content of testfile6
~$ cat testfile7 //displays the content of testfile7
~$ comm testfile6 testfile7
In output of the above command,
First column shows distinct lines in testfile6
Second column shows distinct lines in testfile7
Third column shows lines common in both files

The head command, as the name suggesting that it display the first N
lines of given input file content. By default, the value of N is 10 lines.
While no option is mentioned then, by default, it display first 10 lines of the file
content.
example:
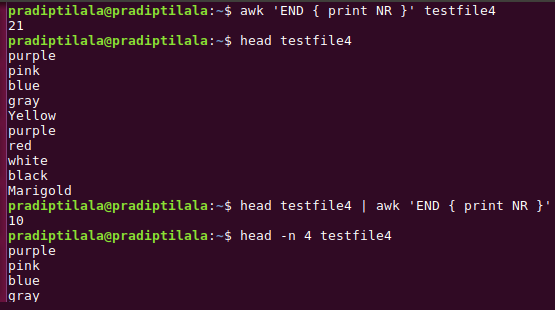
~$ awk 'END { print NR}' testfile4 //prints the count of lines in testfile4
~$ head testfile4 //by default(with no options), prints first 10 lines in testfile4
~$ head testfile4 | awk 'END { print NR} '//pipeline with above command, prints the count of lines
~$ head -n 4 testfile4 //prints first 4 lines in testfile4

5. paste command:
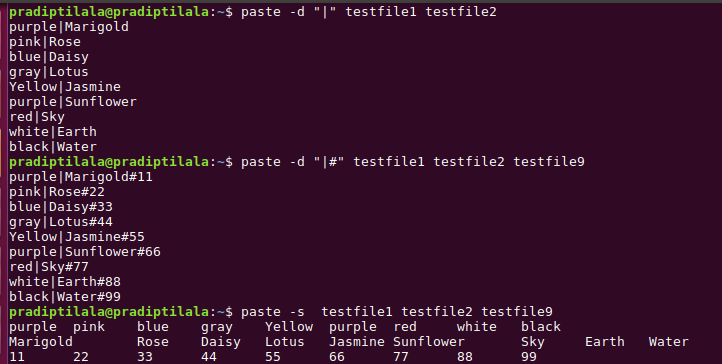
~$ paste -d "|" testfile1 testfile2 //merge parallel and delimiter- "|"
In output, the first column consist of content of testfile1 and second column represent the content of testfile2 separated by delimiter "|" .
~$ paste -d "|#" testfile1 testfile2 testfile9 //merge parallel and delimiter-"|", "#" used as in image
~$ paste -s testfile1 testfile2 testfile9 //merge horizontally and default delimiter- TAB

6. sed command:
example:
~$ awk 'END { print NR}' testfile4 //prints the count of lines in testfile4
~$ head testfile4 //by default(with no options), prints first 10 lines in testfile4
~$ head testfile4 | awk 'END { print NR} '//pipeline with above command, prints the count of lines
~$ head -n 4 testfile4 //prints first 4 lines in testfile4
- It is used to merge files in horizontal/parallel manner consisting of lines from each specified file to output, separated by tab (delimiter).
- Write lines consisting of the sequentially corresponding lines from each FILE, separated by TABs, to standard output.
~$ paste -d "|" testfile1 testfile2 //merge parallel and delimiter- "|"
In output, the first column consist of content of testfile1 and second column represent the content of testfile2 separated by delimiter "|" .
~$ paste -d "|#" testfile1 testfile2 testfile9 //merge parallel and delimiter-"|", "#" used as in image
~$ paste -s testfile1 testfile2 testfile9 //merge horizontally and default delimiter- TAB
- Sed stands for stream editor. A sed command is used to perform basic text modifications on an input stream (a file or input from a pipeline).
- sed command works by making only one pass over the input(s), and is consequently more efficient. It used in the function on file like, searc, find, replace, insert or delete. most commonly used for substitution.
- By using sed command in UNIX you can edit files without opening it. This way it's much quicker way then to open that file in Editor and then modifying it.
- SED command supports can perform complex pattern matching as it supports regular expression.
~$sed 's/Jul/Oct/2' testfile8
In output, the 2nd occurrence of phrase "Jul" in each line will be replaced by the phrase "Oct" for content of testfile8. If the second occurrence of word "Jul" found in line then, it replaced by "Oct", otherwise, it command for match in the next line.
~$sed 's/Jul/Oct/g' testfile8
In output, the all occurrence of phrase "Jul" in each line will be replaced by the phrase "Oct" for content of testfile8.
~$sed 's/pradip/Pradip/2g' testfile8 //second occurrence of "pradip" replaced to "PRADIP"
In output, starting from the 2nd occurrence each of phrase "Jul" in each line will be replaced by the phrase "Oct" for content of testfile8.

7 . sort command:
~$ cat testfile2 //The file display content of testfile2
~$ sort testfile2 //The file lines are sorted alphabetically.
~$ sort -r testfile2 //The file lines are sorted alphabetically in reverse order.

8 . tail command:
~$tail -5 testfile4 //displays last five lines of testfile4 (total lines are 20)
In output, the 2nd occurrence of phrase "Jul" in each line will be replaced by the phrase "Oct" for content of testfile8. If the second occurrence of word "Jul" found in line then, it replaced by "Oct", otherwise, it command for match in the next line.
~$sed 's/Jul/Oct/g' testfile8
In output, the all occurrence of phrase "Jul" in each line will be replaced by the phrase "Oct" for content of testfile8.
~$sed 's/pradip/Pradip/2g' testfile8 //second occurrence of "pradip" replaced to "PRADIP"
In output, starting from the 2nd occurrence each of phrase "Jul" in each line will be replaced by the phrase "Oct" for content of testfile8.

- Write sorted concatenation of all FILE(s) to standard output.
- sort command can also be used to sort numerically. (if file content is numerical), sort in reverse order, sort alphabetically, sort by month and can also used to remove duplicates.
- By default, if no options specified then, command sorts assuming that the file contents are ASCII, the entire line is taken as sort key and Default field separator will be a Blank space.
~$ cat testfile2 //The file display content of testfile2
~$ sort testfile2 //The file lines are sorted alphabetically.
~$ sort -r testfile2 //The file lines are sorted alphabetically in reverse order.

- The tail command, as the name refers that it display the last N lines of given input content.
- By default, the value of N is 10 lines. While no option is mentioned in command then it display last 10 lines of the file content.
~$tail -5 testfile4 //displays last five lines of testfile4 (total lines are 20)

9 . tr command:
- The tr ("translate" ) is filter command of operating systems like Linux/Unix.
- It is a command line utility to translate, squeeze, and/or delete characters from standard input, writing to standard output.
- It supports transformations like uppercase to lowercase, find and replace character . It can be used to support more complex transformations while used with UNIX pipes.
~$cat testfile3 | tr “[a-z]” “[A-Z]”
In output, it replaces the all LOWERCASE letters to UPPERCASE alphabets with range specified and display translated content of the testfile3.
~$cat testfile3 | tr “[a-w]” “[A-W]”
~$cat testfile3 | tr “[a-w]” “[A-W]”
In output, it replaces the all LOWERCASE letters to UPPERCASE alphabets with range specified and display translated content of the testfile3. If character is not in range then it will not be traslated.
- The uniq command utility will filter adjacent matching lines from INPUT (or standard input), helps to find the adjacent duplicate lines and can be used to delete the duplicate lines and writes to file/OUTPUT (or standard output).
- If no options provided then, matching lines are merged to the first occurrence.
~$cat testfile2 //displays the testfile2
~$uniq testfile2 //in output, repeated lines are removed


No comments:
Post a Comment